X-Diffusion: Training Diffusion Policies on Cross-Embodiment Human Demonstrations

ICRA 2026
Robots and Humans Behave Differently
Adding Noise Makes Human and Robot Actions Indistinguishable
X-Diffusion Pipeline
We convert human videos into robot-aligned state-action pairs using 3D hand-pose estimation and lightweight retargeting, and reduce the visual gap with object masks and keypoint overlays.
Adding noise suppresses embodiment-specific details while preserving task intent. We use a human-vs-robot classifier to find the earliest noise level where human actions are indistinguishable from robot actions and treat them as safe supervision.
Key Results
1) X-Diffusion can train on all human data, while naively training on all human data leads to infeasible robot motions
We compare X-Diffusion with FILTERED (robot-verified human demos only), NAIVE (all human data), and ROBOT (robot-only) and find consistent gains on every task.
2) X-Diffusion outperforms prior cross-embodiment learning baselines
We demonstrate empirically that X-Diffusion outperforms other cross-embodiment learning baselines across all tasks, which see either small performance gains or degraded performance when using all human data.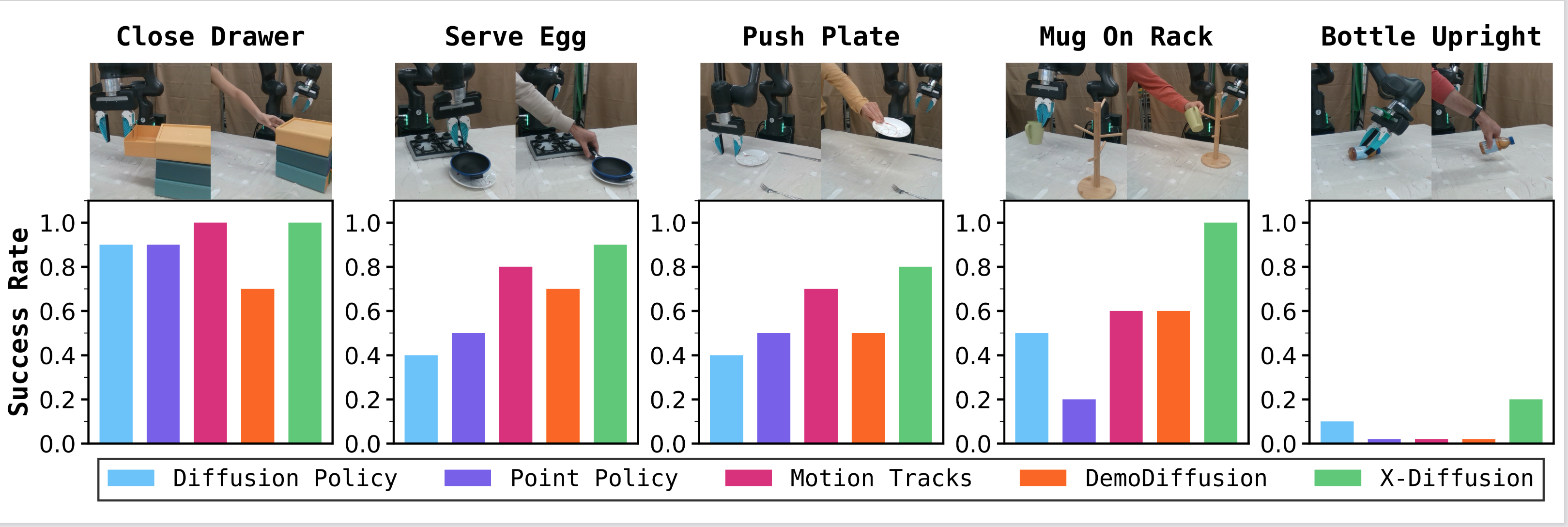
Paper

BibTex
@inproceedings{pace2026xdiffusion,
title={X-Diffusion: Training Diffusion Policies on Cross-Embodiment Human Demonstrations},
author={Maximus A. Pace and Prithwish Dan and Chuanruo Ning and Atiksh Bhardwaj and Audrey Du and Edward W. Duan and Wei-Chiu Ma and Kushal Kedia},
booktitle={IEEE International Conference on Robotics and Automation (ICRA)},
year={2026},
}