
Multi-turn reinforcement learning provides a principled framework for training LLM agents, but exploration remains a key bottleneck. Classical exploration strategies such as epsilon-greedy and upper confidence bounds select random actions, failing to efficiently explore the combinatorial space of multi-turn token sequences. Our key insight is that LLMs can use hindsight to guide exploration: by analyzing completed trajectories and proposing counterfactual actions that could have led to higher returns. We propose HOPE (Hindsight Off-Policy Exploration), which integrates hindsight-guided exploration into both the actor and critic stages of multi-turn RL. HOPE improves the critic's state-action coverage by generating rollouts from counterfactual actions, and steers the actor's exploration in RL by using a learned counterfactual generator to propose alternative actions. Experimental results show that HOPE outperforms strong multi-turn RL baselines in task-oriented dialogue tasks, TwentyQuestions (success: 0.82 -> 0.97), GuessMyCity (success: 0.68 -> 0.75), and tool-use dialogue task CarDealer (success: 0.72 -> 0.77).
HOPE integrates hindsight-guided exploration into both stages of actor critic RL.
(1) Critic: HOPE improves the critic's state-action coverage by generating rollouts with counterfactual actions.
(2) Actor: HOPE biases exploration toward promising regions by sampling candidate actions from a counterfactual proposer and evaluating them via the critic.
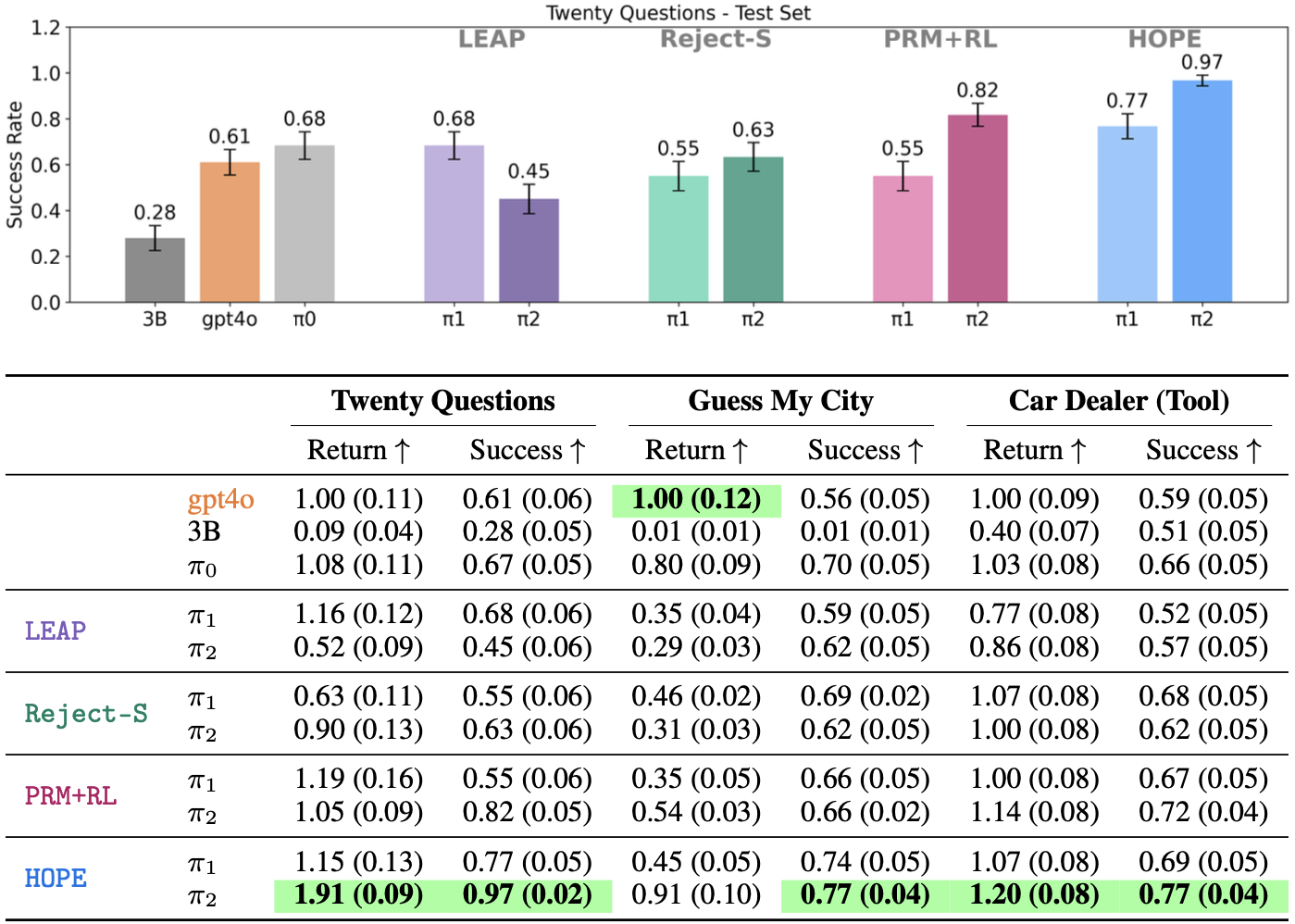
HOPE consistently outperforms state-of the art imitation learning and reinforcement learning baselines across all domains, achieveing success rates of
- Twenty Questions: 0.82 → 0.97
- Guess My City: 0.68 → 0.75
- Car Dealer (Tool): 0.72 → 0.77
Below we report average success rate and normalized return (with respect to gpt4o).
Though additional experiments, we also find the following:
(1) Effectivness in Exploration: HOPE outperforms other naively exploration strategies (e.g., smapling with high temperature, prompting the poliyc to explore)
(2) Optimal Critic Data Mixture: The success rate significantly improves when hindsight data is included, peaking at a data mixture of 40% hindsight data, 60% on-policy data for Twenty Questions domain.
(3) Effectiveness of Hindsight Exploration during Actor Training: During actor training, hindsight-guided exploration improves performance, especially when the critic is only trained on unguided data.

HOPE outperforms unguided exploration strategies (H-Temp, which simply samples actions with high temperature) and guided exploration strategies (Explore-Prompt, which only prompts the policy to explore more).
By proposing counterfactual actions based on summary of completed trajectories, HOPE leads the policy to explore high-value states and actions, resulting in more successful trajectories.
